Introducción#
Los bump charts son una herramienta poderosa en visualización de datos que permite mostrar cambios en rankings entre diferentes categorías o grupos. Aquí documentaré cómo repliqué un bump chart profesional creado en Tableau y publicado originalmente en Visual Capitalist, usando R y ggplot2.
Este es el gráfico original (interactivo) que replicaremos en R, estático: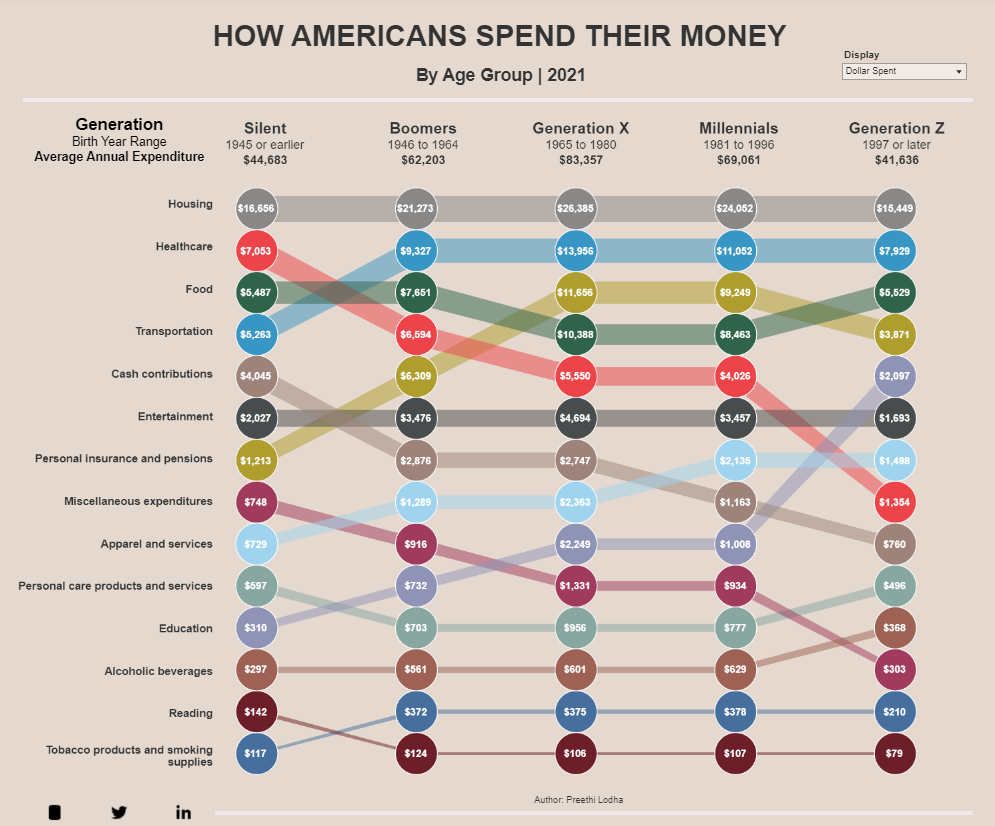
Su objetivo es visualizar cómo diferentes generaciones de estadounidenses distribuyen sus gastos en 14 categorías, desde la generación Silent (nacidos en 1945 o antes) hasta la Generación Z (nacidos en 1997 o después). El análisis se basa en datos de la Consumer Expenditure Survey del U.S. Bureau of Labor Statistics de 2021.
¿Qué es un bump chart?#
Un bump chart es un tipo especializado de gráfico de líneas que enfatiza cambios de posición o ranking en lugar de valores absolutos. A diferencia de los gráficos de líneas tradicionales, el eje Y representa posiciones ordinales (1º, 2º, 3º…) en lugar de valores continuos.
Casos de uso ideales#
Los bump charts son especialmente útiles para:
- Visualizar competencia: Mostrar cómo cambian las posiciones relativas entre competidores a lo largo del tiempo
- Analizar rankings: Seguir el rendimiento de categorías en clasificaciones (deportes, ventas, preferencias)
- Comparar prioridades: Entender qué es más o menos importante para diferentes grupos
- Detectar patrones: Identificar tendencias de ascenso, descenso o estabilidad en las posiciones
En nuestro caso, el bump chart revela qué categorías de gasto son prioritarias (tienen mayor ranking) para cada generación.
Contexto del gráfico original#
El gráfico original fue creado por Preethi Lodha y publicado en Visual Capitalist en septiembre de 2022. Utiliza Tableau para crear una visualización interactiva, pero en este tutorial replicaremos la versión estática usando únicamente R.
Los datos provienen de la tabla 2602 del Bureau of Labor Statistics: “Generation of reference person: Annual expenditure means, shares, standard errors, and coefficients of variation” del año 2021.
Preparación del entorno#
Instalación de paquetes#
Primero, hay que instalar los paquetes necesarios:
# Instalar paquetes si no los tienes
install.packages(c("tidyverse", "ggplot2", "ggtext", "grid"))Cargar librerías#
# Cargar librerías necesarias
library(tidyverse) # Manipulación de datos
library(ggplot2) # Creación de gráficos
library(ggtext) # Renderizado de texto HTML/Markdown
library(grid) # Elementos gráficos adicionalesImportación y preparación de datos#
Cargar los datos#
Los datos están disponibles en formato CSV en mi repositorio de GitHub:
# Importar datos desde GitHub
df <- read_csv("https://github.com/castellco/bump-chart/raw/main/data.csv")
# Visualizar las primeras filas
head(df)La estructura original contiene una fila por generación y una columna por categoría de gasto:
# A tibble: 5 × 15
generation housing healthcare food transportation cash_contributions
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 silent 16656 7053 5487 5263 4045
2 boomers 21273 6594 7651 9327 2876
3 gen_X 26385 5550 10388 13956 2747
4 millennials 24052 4026 8463 11052 1163
5 gen_Z 15449 1354 5529 7929 760Transformar a formato long#
Para crear un bump chart, necesitamos transformar los datos de formato “wide” a “long”, donde cada fila representa una combinación de generación y categoría de gasto:
# Pivotar a formato long y calcular rankings
df <- df %>%
# Convertir de wide a long
pivot_longer(-generation, names_to = "variables", values_to = "dollars") %>%
# Agrupar por generación
group_by(generation) %>%
# Ordenar por monto gastado (descendente)
arrange(generation, desc(dollars)) %>%
# Asignar ranking dentro de cada generación
mutate(ranking = row_number()) %>%
ungroup()Renombrar categorías para mejor legibilidad#
# Renombrar generaciones
df$generation[df$generation == "silent"] <- "Silent"
df$generation[df$generation == "boomers"] <- "Boomers"
df$generation[df$generation == "gen_X"] <- "Generation X"
df$generation[df$generation == "millennials"] <- "Millennials"
df$generation[df$generation == "gen_Z"] <- "Generation Z"
# Renombrar categorías de gasto con nombres completos
df$variables[df$variables == "alcohol"] <- "Alcoholic beverages"
df$variables[df$variables == "apparel"] <- "Apparel and services"
df$variables[df$variables == "cash_contributions"] <- "Cash contributions"
df$variables[df$variables == "education"] <- "Education"
df$variables[df$variables == "entertainment"] <- "Entertainment"
df$variables[df$variables == "food"] <- "Food"
df$variables[df$variables == "healthcare"] <- "Healthcare"
df$variables[df$variables == "housing"] <- "Housing"
df$variables[df$variables == "insurance"] <- "Personal insurance and pensions"
df$variables[df$variables == "miscellaneous"] <- "Miscellaneous expenditures"
df$variables[df$variables == "personal_care"] <- "Personal care products and services"
df$variables[df$variables == "reading"] <- "Reading"
df$variables[df$variables == "smoking"] <- "Tobacco products and smoking \n supplies"
df$variables[df$variables == "transportation"] <- "Transportation"Formatear valores monetarios#
# Formatear la columna de dólares para mostrar con separador de miles
df$dollars <- format(df$dollars, big.mark = ",", trim = TRUE)
df$dollars <- paste0("$", df$dollars)Diseño de etiquetas enriquecidas#
Una característica distintiva de este bump chart es el uso de etiquetas enriquecidas con HTML que muestran múltiples niveles de información en el eje X.
Crear vectores de etiquetas#
# Orden cronológico de las generaciones
x_names_ordered <- c("Silent", "Boomers", "Generation X", "Millennials", "Generation Z")
# Etiquetas enriquecidas con HTML
x_names_full <- c(
paste("<span style='font-size: 9.55pt'>**Silent**</span>",
"1945 or earlier",
"**$44,683**",
sep = "<br>"),
paste("<span style='font-size: 9.55pt'>**Boomers**</span>",
"1946 to 1964",
"**$62,203**",
sep = "<br>"),
paste("<span style='font-size: 9.55pt'>**Generation X**</span>",
"1965 to 1980",
"**$83,357**",
sep = "<br>"),
paste("<span style='font-size: 9.55pt'>**Millennials**</span>",
"1981 to 1996",
"**$69,061**",
sep = "<br>"),
paste("<span style='font-size: 9.55pt'>**Generation Z**</span>",
"1997 or later",
"**$41,636**",
sep = "<br>")
)
# Etiqueta para el eje X completo
x_lab <- paste(
"<span style='font-size: 10pt'>**Generation**</span>",
"Birth Year Range",
"**Average Annual Expenditure**",
sep = "<br>"
)Estas etiquetas proporcionan tres niveles de información:
- Nombre de la generación (en negrita)
- Rango de años de nacimiento
- Gasto anual promedio total (en negrita)
Construcción del tema personalizado#
Un tema visual coherente es fundamental para la efectividad del bump chart. Vamos a crear theme_bump() que define todos los aspectos estéticos del gráfico. Si bien es posible usar temas predefinidos como theme_minimal() o theme_classic(), crear un tema personalizado permite controlar cada detalle, que es lo que necesitamos para replicar fielmente el diseño original.
Definir colores#
# Paleta de colores
color_background <- "#e5d9cf" # Fondo cálido
color_text <- "#333333" # Texto oscuroCrear el tema#
theme_bump <- function() {
theme_bw(base_size = 15) +
# Fondos
theme(panel.background = element_rect(fill = color_background, color = color_background)) +
theme(plot.background = element_rect(fill = color_background, color = color_background)) +
theme(panel.border = element_rect(color = color_background)) +
theme(strip.background = element_rect(fill = color_background, color = color_background)) +
# Cuadrícula
theme(axis.ticks = element_blank()) +
theme(panel.grid = element_line(colour = color_background)) +
# Leyenda (no se muestra)
theme(legend.position = "none") +
# Caption
theme(plot.caption = element_text(hjust = 0.6, vjust = 0.1, size = 5.45)) +
# Títulos
theme(plot.title = element_text(color = color_text, size = 17.5, face = "bold",
hjust = 0.5, margin = margin(0,0,10,0))) +
theme(plot.subtitle = element_text(color = color_text, size = 11, hjust = 0.5,
face = "bold", margin = margin(0,0,22,0))) +
# Ejes
theme(axis.title.x = element_blank()) +
theme(axis.title.y = element_blank()) +
theme(axis.text = element_markdown()) +
theme(axis.text.x.top = element_markdown(color = "#3b3b3a", family = "Arial Narrow", size = 7.5)) +
theme(axis.text.y = element_blank()) +
# Tag (etiqueta adicional)
theme(plot.tag = element_markdown(family = "Arial Narrow", lineheight = 0.1, size = 8)) +
theme(plot.tag.position = c(0.10, 0.85)) +
# Márgenes
theme(plot.margin = unit(c(0.5, 0.4, 0.5, 0.65), "cm"))
}Construcción del bump chart#
Ahora viene la parte más importante: ensamblar todos los elementos para crear el bump chart.
replica <- ggplot(
data = df,
aes(x = generation, y = ranking, group = variables)) +
# Aplicar tema personalizado
theme_bump() +
# Líneas conectando los puntos (grosor varía según ranking)
geom_line(aes(color = variables, alpha = 1, linewidth = rev(ranking))) +
# Puntos con borde blanco
geom_point(size = 11.85, color = "white") +
geom_point(aes(color = variables), size = 11.3) +
# Invertir eje Y (ranking 1 arriba)
scale_y_reverse(breaks = 1:nrow(df)) +
# Configurar eje X con etiquetas enriquecidas
scale_x_discrete(
limits = x_names_ordered,
labels = x_names_full,
position = "top",
expand = expansion(mult = c(0.356, 0.1))
) +
# Títulos y caption
labs(
title = "HOW AMERICANS SPEND THEIR MONEY",
subtitle = "By Age Group | 2021",
caption = "Author: Preethi Lodha",
tag = x_lab
) +
# Permitir elementos fuera del área de trazado
coord_cartesian(clip = "off") +
# Líneas horizontales blancas superior e inferior
annotation_custom(linesGrob(x = c(0, 0.99), y = c(1.11, 1.11),
gp = gpar(col = "#f0eae8", lwd = 2.8, lineend = "square"))) +
annotation_custom(linesGrob(x = c(0, 0.99), y = c(-0.05, -0.05),
gp = gpar(col = "#f0eae8", lwd = 2.8, lineend = "square"))) +
# Etiquetas de categorías en el eje Y
geom_text(data = df %>% filter(generation == "Silent"),
aes(label = variables, x = 0.72236),
hjust = "outward", fontface = "bold", color = "#272727", size = 2.4) +
# Montos gastados dentro de los puntos
geom_text(aes(label = dollars), hjust = "center", color = "white",
size = 2.25, fontface = "bold") +
# Paleta de colores personalizada
scale_color_manual(values = c(
"#9c6255", "#a0d4ee", "#9d8379", "#8f93b5", "#494c4d", "#2f634a", "#ed444a",
"#8a8887", "#a13b5d", "#87a7a0", "#af9e2e", "#6d1f29", "#466f9d", "#3896c4"
))
# Mostrar el gráfico
replica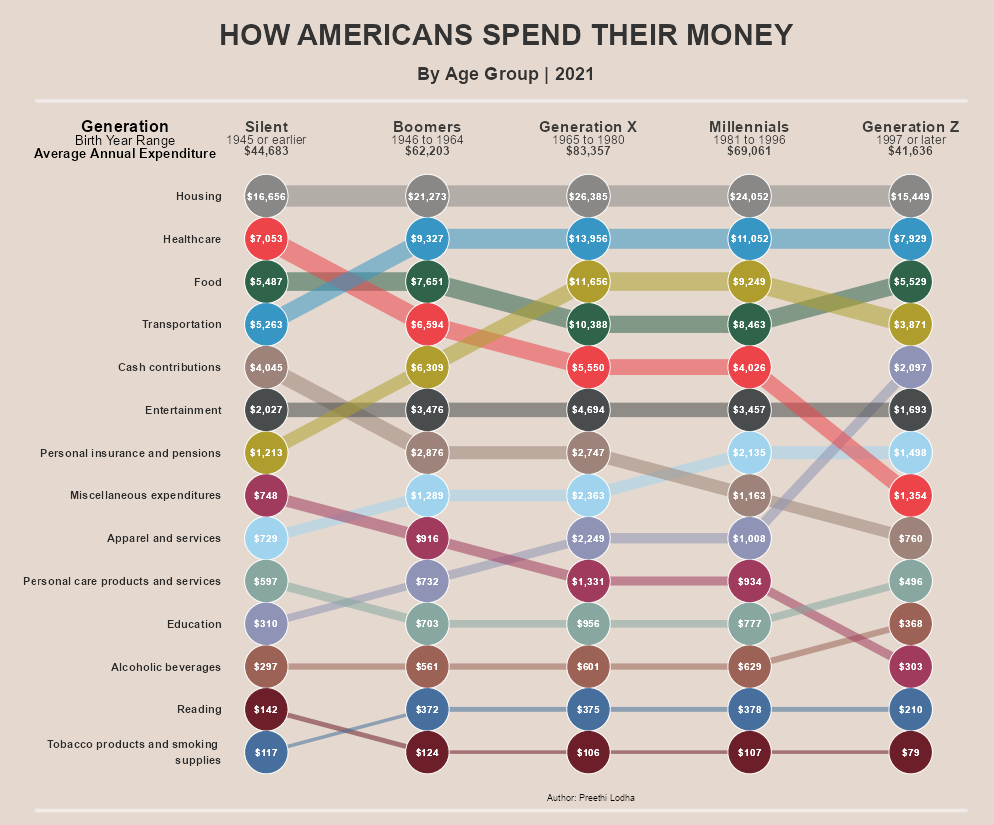
Guardar el gráfico#
Para exportar el gráfico en alta calidad:
ggsave("bump_chart_replica.png",
plot = replica,
width = 8.29,
height = 6.88,
units = "in",
dpi = 300) # Alta resoluciónComparación con el original#
Este es el gráfico original publicado en the Visual Capitalist, en Tableau:
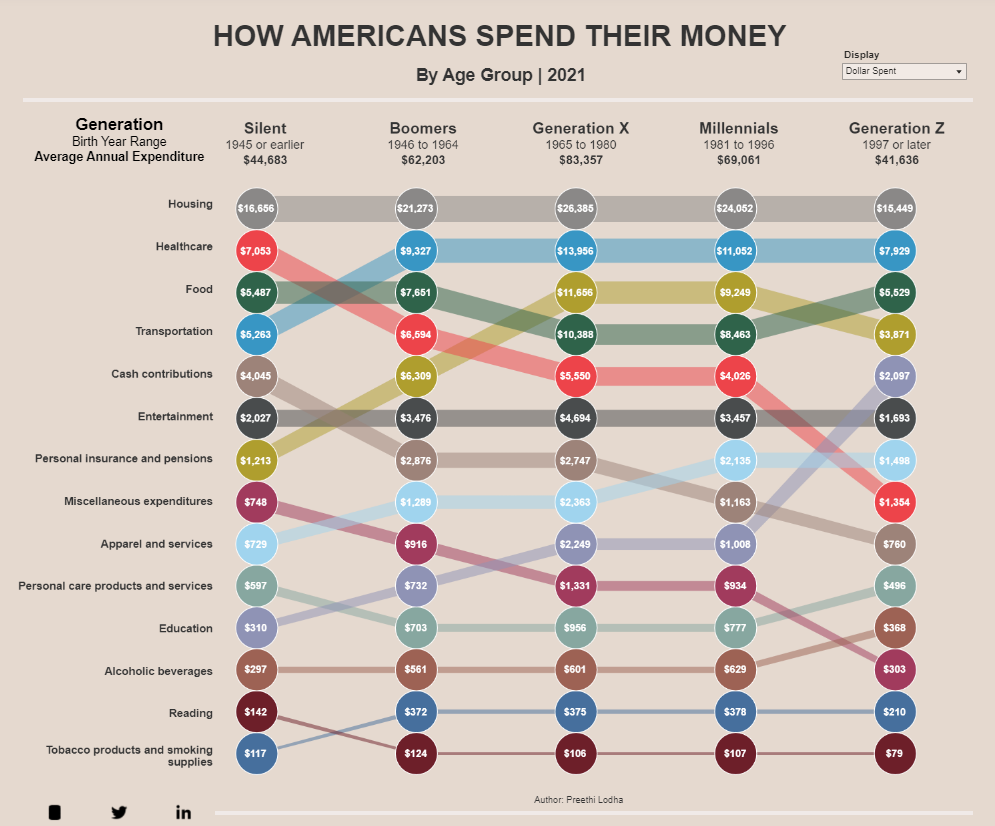
Esta es mi réplica en R, con ggplot2: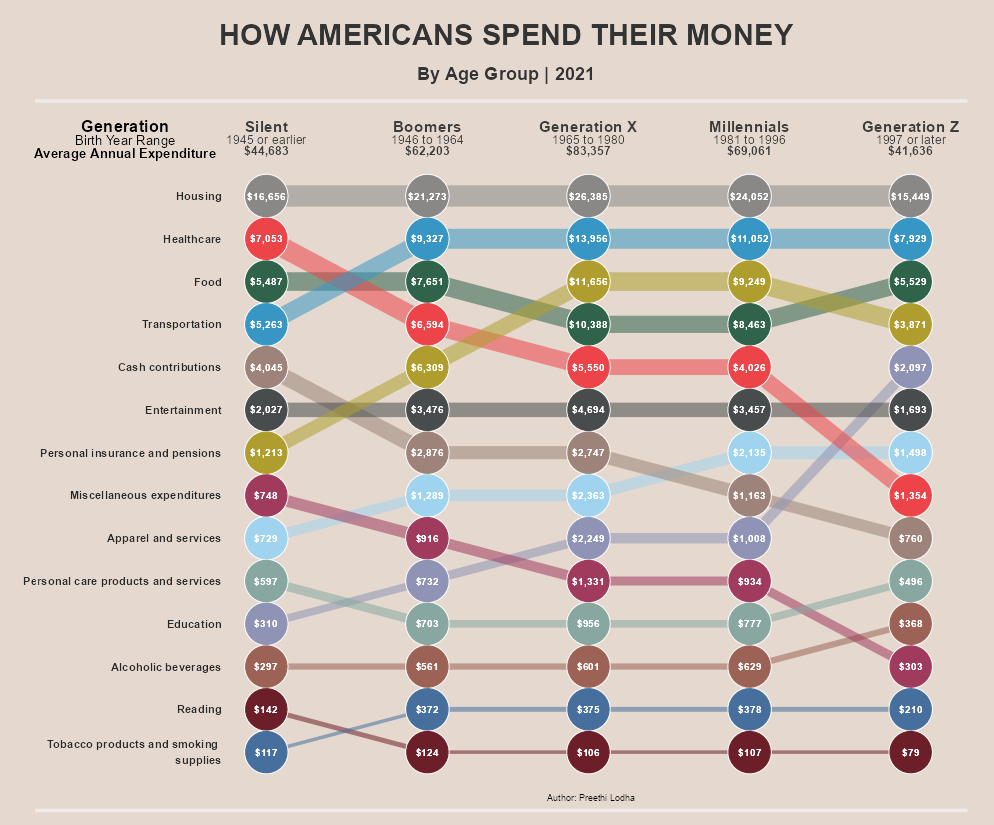
Como se puede ver, la réplica captura fielmente todos los elementos visuales del original, excepto los componentes interactivos (que no son necesarios para la versión estática). Los elementos clave replicados incluyen:
- Líneas de grosor variable según el ranking
- Puntos con borde blanco para mejor visibilidad
- Etiquetas enriquecidas con múltiples niveles de información
- Paleta de colores distintiva para cada categoría
- Diseño limpio con fondo cálido
- Cantidades monetarias dentro de cada punto
Insights del gráfico#
Del bump chart podemos extraer varios hallazgos interesantes sobre los patrones de gasto generacional:
Housing domina universalmente: La vivienda es el mayor gasto para todas las generaciones, ocupando consistentemente el primer lugar.
Transportation mantiene alta prioridad: El transporte se posiciona en los primeros lugares, especialmente para Generation X y Millennials en sus años de mayor actividad laboral.
Healthcare aumenta con la edad: Los gastos en salud muestran una trayectoria ascendente dramática para generaciones mayores (Silent y Boomers).
Education es prioritaria para jóvenes: Las generaciones más jóvenes (Gen Z y Millennials) priorizan más la educación, reflejando posiblemente el aumento de costos universitarios.
Patrones de convergencia y divergencia: Mientras categorías básicas como “Food” mantienen posiciones estables, gastos discrecionales como “Entertainment” varían considerablemente entre generaciones.
Consideraciones técnicas importantes#
Manejo del grosor de línea#
El código usa linewidth = rev(ranking) para variar el grosor de las líneas según el ranking. Esto proporciona una señal visual adicional sobre la importancia relativa de cada categoría, aunque su efecto es sutil.
Posicionamiento de etiquetas#
Las etiquetas de categorías se posicionan usando:
geom_text(data = df %>% filter(generation == "Silent"),
aes(label = variables, x = 0.72236))El valor 0.72236 fue ajustado manualmente para lograr el alineamiento perfecto. Este tipo de ajustes finos son comunes al crear visualizaciones personalizadas.
Múltiples capas de texto#
El código incluye tres llamadas casi idénticas a geom_text() para los montos:
geom_text(aes(label = dollars), ..., size = 2.25, ...) +
geom_text(aes(label = dollars), ..., size = 2.253, ...) +
geom_text(aes(label = dollars), ..., size = 2.257, ...)Esta técnica crea un efecto de negrita más pronunciado mediante la superposición ligera de texto con tamaños incrementales.
Código completo y reproducibilidad#
El código completo y los datos están disponibles en mi repositorio de GitHub:
- Repositorio: https://github.com/castellco/bump-chart
- Proyecto original: https://csslab.uc3m.es/dataviz/projects/2022/100481925/
Referencias#
Fuentes de datos#
U.S. Bureau of Labor Statistics. (2022). Consumer Expenditure Survey, 2021. Recuperado de https://www.bls.gov/cex/
Gráfico original#
Lodha, P. (2022). How Do Americans Spend Their Money, By Generation? Visual Capitalist. https://www.visualcapitalist.com/cp/how-americans-spend-their-money-2022/
Documentación técnica (proyecto original)#
Wickham, H. (2016). ggplot2: Elegant Graphics for Data Analysis (2nd ed.). Springer-Verlag New York. https://ggplot2.tidyverse.org
Wickham, H., François, R., Henry, L., Müller, K., & Vaughan, D. (2023). dplyr: A Grammar of Data Manipulation. R package version 1.1.0. https://CRAN.R-project.org/package=dplyr
Wilke, C. O. (2023). ggtext: Improved Text Rendering Support for ‘ggplot2’. R package version 0.1.2. https://CRAN.R-project.org/package=ggtext
Material del proyecto#
Cornejo Castellano, C. (2023). Bump chart: How Americans spend their money. UC3M Data Visualization Projects. https://csslab.uc3m.es/dataviz/projects/2022/100481925/
Cornejo Castellano, C. (2025). Bump Chart Tutorial - GitHub Repository. https://github.com/castellco/bump-chart